To help organize the various parts of the platform, I’ve put together a few diagrams. They’re rather rough, but are a good method to work through what’s involved.
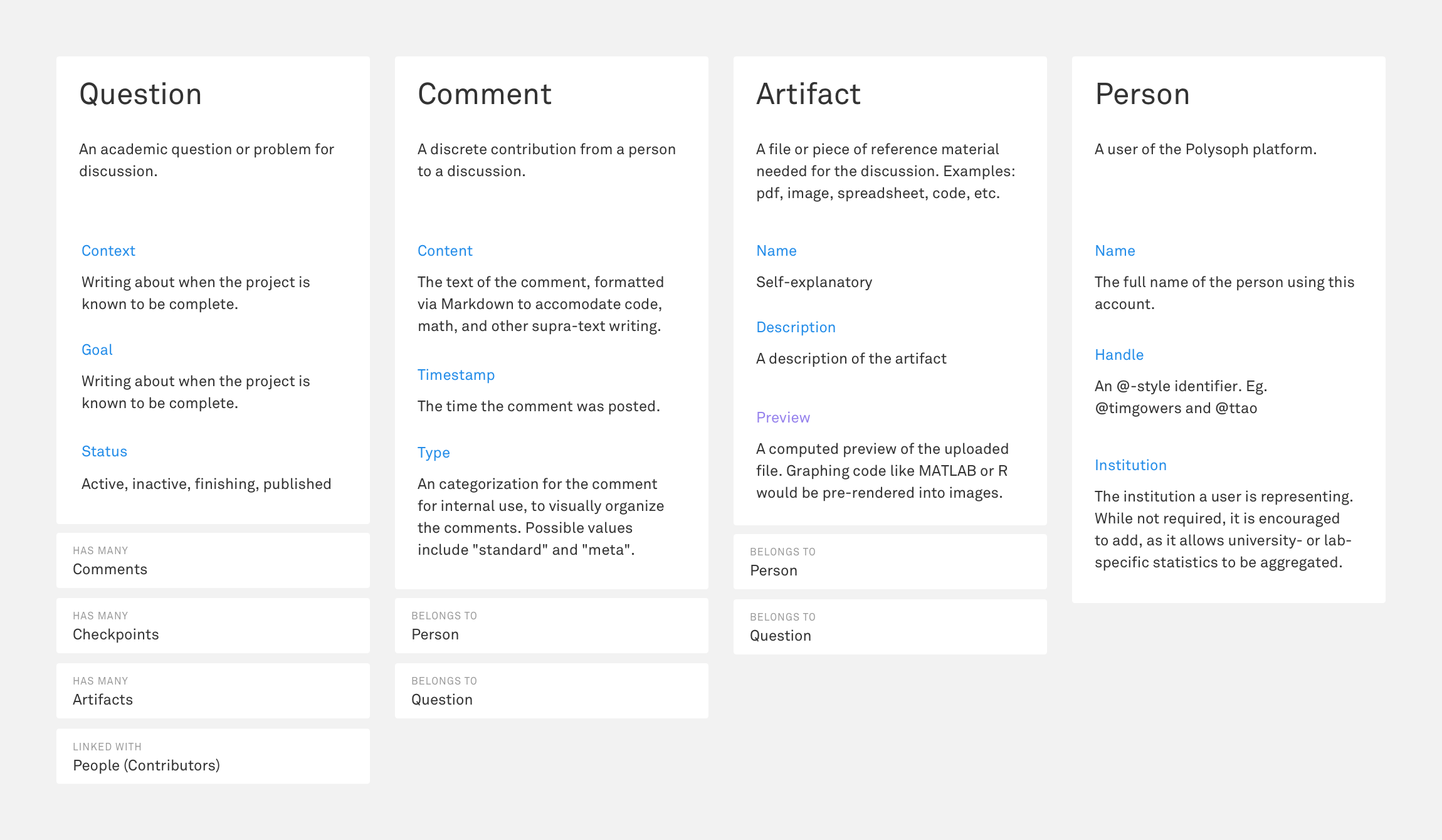
A listing of four fundamental objects in the system and a few of their properties and relationships. Hardly exhaustive, but enough to get started coding.
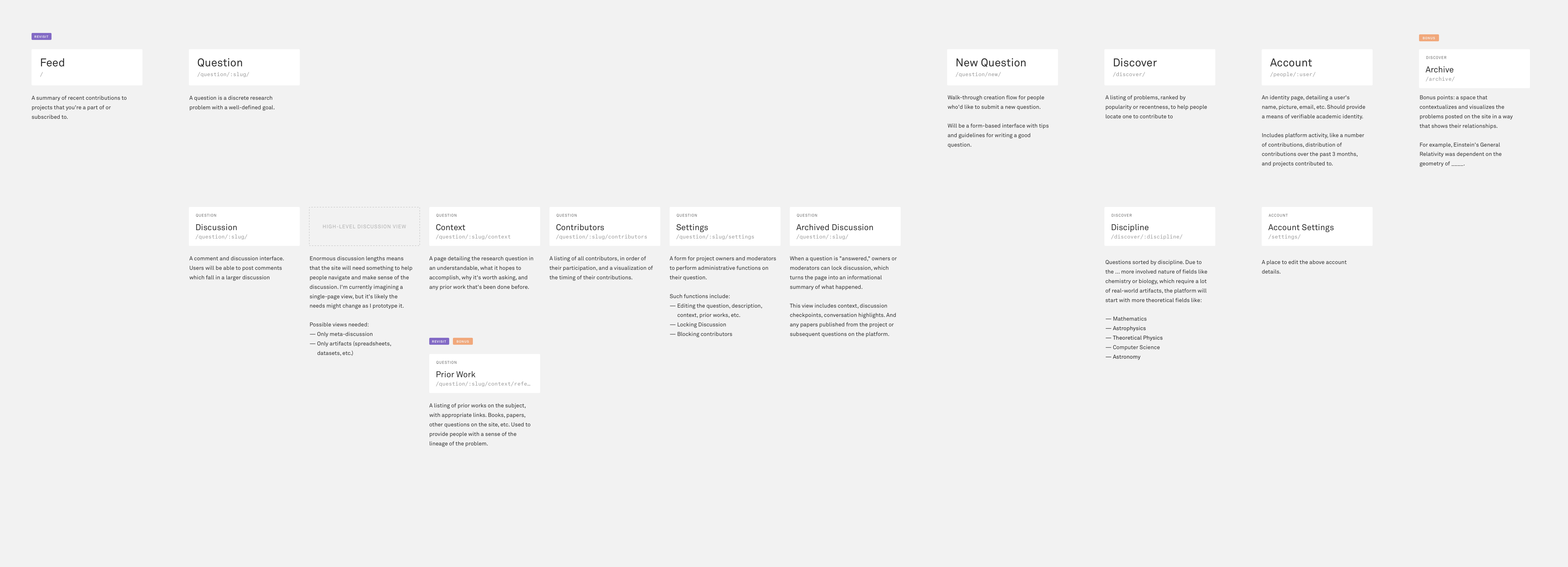
Since there are a lot of potential problem areas, I put together a site map to help scope out what I’m hoping to tackle for the rest of this project. It’s pretty implicit at the moment, so apologies for the digging required to interpret what’s going on.
A sampling of a few of the pages that will be contained on the site. View the full sitemap.
From here I’ll begin to flesh out the required content for the various parts of the application between code and a few small mockups.
Since the primary workflow of the application will be discussion, I’ve opted to look at Polymath 1—the initial project that sparked this thesis—for an understanding of the problems and structures of collaborative research discussions.
Polymath 1, initiated by mathematician Timothy Gowers, focused on providing a combinatorial proof to the Hales-Jewitt theorem.
While the project had a slow first few hours, it quickly picked up, garnering the attention of many mathematicians. Over the course of 112 days (16 weeks), 133 contributors developed this proof by working together over Timothy Gowers’ blog.
To learn more about the project, I dissected how the conversation happened. Below, I’ve listed a few key observations.
A. Discussions are really, really long
The most noticeable aspect of the discussion is it’s length. It’s obscenely long, with over 1270 total comments, most averaging well over 100 words. The first page alone has 181 comments, and the whole discussion ended up spreading out over 12 separate blog posts to avoid overloading the blog platform.
This length also presented referential issues. The sheer scale made it easy to lose track of ideas that were introduced in the beginning. At comment #300, Tim Gowers introduced the practice of a comment numbering system.
Similarly, to enable sub-conversations in the larger stream, contributors began to start their comments with “Thread Title: X” to provide a work-around for a feature like in-line threading.
Take-aways
Have a means to reference different points in the discussion.
Have a means to “checkpoint” the discussions. People should summarize what’s been done so far, and what the next steps are. This helps new people jump in a bit more easily.
Consider micro-discussions that naturally emerge and disappear as ideas develop. Are there any opportunities there?
How might the (potential) scale of discussion impact features like notifications?
Much of this initial writing was essential in how people remained cohesive as a group. Decisions like a change of approach is documented and discussed, before being followed for the next two posts—a practice that stemming directly from the guidelines.
Gowers’ introductions also started out by providing 38 (!) initial steps, all of which were very brief ideas, but ones that kick-started the discussion. They provide ground-work for people to start talking and thinking about.
Takeaways
Provide discussion guidelines to help encourage a culture of meaningful contributions.
Encourage project owners to provide starting ideas.
C. Linear discussion gave cohesion
As laid out in the previously mentioned participation guidelines the discussion must remain focused on the current approach, or be focused on changing the approach. People shouldn’t try to fork the conversation. This linearity was afforded by how Wordpress does comments, but it provides the community with a clear sense of cohesion and direction.
Take-aways
What would branching look like? Would it help or hurt the project?
D. There’s lots of meta-discussion
Throughout all twelve posts, the conversation is littered with posts about how to write LaTeX comments, or recommendations for ways to comment. Everyone was figuring out how to work as they went.
To help distinguish themes comments, people began to annotate them by writing “metacomment” at the beginning.
Take-aways
Consider how to keep discussions focused. This may mean having a separate space for meta-discussion, or being able to filter and hide such comments in the same view.
E. Small Ideas
Contributors made heavy use of LaTeX in their comments. Supporting existing languages for notation in different fields seems pretty essential to creating a good user experience.
A lot of comments made references to other people and other comments. The linear comment structure is limiting, evidenced by their referencing viacreated indices (eg. “423. Comment Title”, and “In response to #109”)
People wanted to go back and edit past comments to correct errors. Though in the linked instance, the error was due to the fact that comment indices were done manually.
On Wednesday I sat down with John Dupuis, the head librarian of the York Steacie Science Library, to talk about what’s happening in the open science world, and to get some feedback on a few of my ideas so far.
As an active proponent of open science, he shared with me a number of projects that leverage similar ideas as my project.
Talking with John led me to two conclusions. First, the modularity of the initiative seems to be an important factor in the success of online collaboration. A single research question must be broken down into manageable components that individuals can come in and contribute to. Github accomplishes this through the splitting of work into issues and pull requests, with the former being low-effort, the latter being high-effort.
Zooniverse, a web-based tool for citizen participation in science.
A successful example of this in the sciences is Zooniverse, a project to enable citizen contributions to science by performing menial tasks that can’t easily be automated. Zooniverse has been very successful, I think in part because of how it makes contribution very easy and well-defined.
This echoes the real world, where research groups often collaborate by breaking down questions into discrete modules of work, owned by individual researchers. Sometimes these modules are more technical or task-oriented in nature (eg. gathering data, writing the paper), and other times they’re more abstract and intellectual (eg. “analyzing the data”). But the discrete roles help the work come together, even on papers with thousands of contributors.
Second, the tools and artifacts used to work through problems varies widely between disciplines. The Polymath Project was “straightforward” in the sense that mathematics is one of the “cleanest” disciplines of inquiry: no external artifacts are needed, only words and calculations to develop ideas. This is different from fields like chemistry or biology, where much of the action takes places through lab trials and physical measurements.
Either this tool needs to focus on a single discipline, or find ways of integrating the different workable pieces of information for different disciplines (maybe like Slack‘s notion of integrations?) The former is probably preferrable.
On Saturday, I had the chance to attend OpenCon 2015, an offshoot from a larger conference in Brussels about the future of open access, open data, and open science.
Hosted at the Mozilla’s Toronto office, the event involved talks from a number of local open science advocates, such as John Dupuis, head of York University’s Steacie Science Library, and Keith McDonald, the City of Toronto’s Open Data Lead.
John Dupuis speaking at OpenCon 2015. Photo by Lorraine Chuen.
Arliss Collin’s talk Building Open Projects on the Web shared interesting initiatives like Software Carpentry, a workshop series to introduce scientists to the technical skills they need to manipulate and work with digital data, and Mozilla Science Lab’sCollaborate project, which helps scientists call for the help of external collaborators when their research leads them to areas outside of their expertise.
These initiatives seem to validate the need for a means for researchers to collaborate, but in a different way that I originally thought. This collaboration is about supplementing skills rather than knowledge. This raises a question: is what I’m making about addressing large and unsolvable scientific problems, like the Polymath Project? Or is it about building an everyday tool. Which is more valuable? And to whom?
While I started my process blog over on this tumblr, I thought it best to leave it as an archive of some initial visual research, and the process of coming up with a topic.
In lieu of the tumblr, I’ve set up the blog you’re reading right now. I hope to use this space to start archiving some of the logic and decisions that get made for this project.
I’ve also created a Github org. Feel free to follow my progress there as well. Open access, and all that, right?





{kind=link}